[Grind75-LeetCode] Word Ladder - Hard
접근
- bfs
풀이
시작 단어와 목표가 될 끝 단어가 존재하고 단어 리스트에 있는 단어들을 타고 끝 단어에 도착할 수 있는지 구하는 문제이다. 시작 단어를 단어 리스트에 있는 문자들로 변환할 수 있다면 변환하며 끝 문자를 만드는 데 걸리는 횟수를 구하는 것이 목표인데 변환이 가능한 기준은 각 단어가 문자 한 개만 다르다면 변환이 가능하다. 알파벳 단위로 시작 단어가 hot이고 리스트 내에 hit이라는 단어가 존재한다면 두 번째 문자인 o과 i만 다르고 나머지가 동일하기 때문에 변환이 가능하다.
이 문제는 옛날에 코딩 테스트를 준비하며 공부할 때 풀었던 문제이다. 프로그래머스의 단어 변환이라는 문제로 프로그래머스 기준 레벨 3의 문제였다. 프로그래머스 코딩 테스트 문제 풀이 전략이라는 책을 보며 공부할 때 완전 탐색 기반의 문제로 등장했었고 코드를 가져와서 돌려봤다.
private class State{
public final String word;
public final int step;
private State(String word, int step){
this.word = word;
this.step = step;
}
}
private boolean isConvertable(String src, String dst){
char[] srcArr = src.toCharArray();
char[] dstArr = dst.toCharArray();
int diff = 0;
for(int i = 0; i < srcArr.length; i++){
if(srcArr[i] != dstArr[i]) diff++;
}
return diff == 1;
}bfs 큐에 들어갈 상태를 나타내는 클래스와 단어 변경이 가능한 지 검사하는 메서드이다. 객체의 경우 현재 단어와 변환 횟수를 저장하고 체크 메서드의 경우 두 단어를 비교해 다른 부분이 1개라면 변환이 가능하다고 반환하는 메서드이다.
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
boolean[] isVisited = new boolean[wordList.size()];
Queue<State> que = new LinkedList<>();
que.add(new State(beginWord, 1));
while(!que.isEmpty()){
State state = que.poll();
if(state.word.equals(endWord)){
return state.step;
}bfs를 이용해 풀다 보니 큐를 이용하게 된다. 초기 상태를 큐에 넣고 bfs를 실행해 준다. 프로그래머스의 문제는 변환 횟수를 구하는 것이었지만 이 문제는 최소 변환 시퀀스가 몇 개냐를 구해야 하기 때문에 시퀀스 내에 들어있는 모든 단어의 개수를 반환해야 해 초기 값이 1이 된다. 만약 현재 단어가 마지막 단어와 같다면 변환 횟수를 반환해 준다.
for(int i = 0; i < wordList.size(); i++){
String next = wordList.get(i);
if(!isConvertable(state.word, next)){
continue;
}
if(isVisited[i])
continue;
isVisited[i] = true;
que.add(new State(next, state.step + 1));
}
}
return 0;
}bfs를 수행하는 부분으로 리스트에 단어들 중 변환이 가능한 단어가 있다면 다음 상태로 추가하고 방문 체크를 하게 된다.
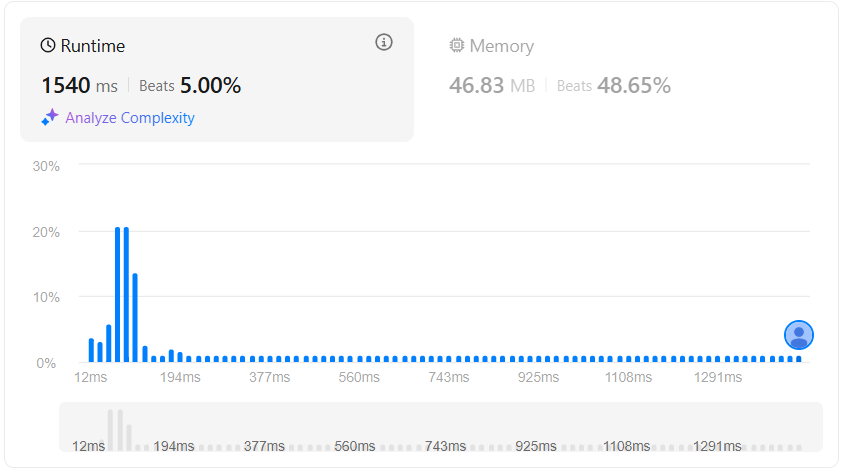
말 그대로 완전 탐색을 수행하기 때문에 성능이 잘 나오진 않을 거 같다 했는데 이렇게 심각한 차이가 날 줄은 몰랐다.
패턴
저기 제일 많은 코드가 제출된 곳을 봤다. bfs로 푸는 방식 자체는 동일했지만 어떤 처리를 해서 성능 차이가 이렇게 나는지 분석해 봤다.
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// Create a set of words for quick lookup
Set<String> wordSet = new HashSet<>(wordList);
if (!wordSet.contains(endWord)) {
return 0; // No possible transformation
}일단 단어들을 Set에 넣고 관리하는 듯했다. 그리고 결과 단어가 단어 리스트에 없다면 변환이 불가능으로 처리를 해주는 코드이다.
// Preprocess the word list to create the adjacency map
Map<String, List<String>> adjacencyMap = new HashMap<>();
int wordLength = beginWord.length();
for (String word : wordSet) {
for (int i = 0; i < wordLength; i++) {
// Create patterns by replacing each character with '*'
String pattern = word.substring(0, i) + '*' + word.substring(i + 1);
adjacencyMap.computeIfAbsent(pattern, k -> new ArrayList<>()).add(word);
}
}단어 리스트를 통해 각 단어의 인접 관계 맵을 만드는 코드이다. 각 단어들을 패턴으로 만들어 저장하는 방식인데 예를 들어 hot라면 각 문자를 *로 치환해 *ot, h*t, ho* 형태의 패턴을 각각 만들어 내고 key 값으로 사용한 뒤 원본 단어를 value로 넣는 것이다.
beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
//만들어진 map 내부 모습
[
"*ot" -> ["hot", "dot", "lot"],
"h*t" -> ["hot"],
"ho*" -> ["hot"],
"d*t" -> ["dot", "dog"],
"do*" -> ["dot", "dog"],
"*og" -> ["dog", "log", "cog"],
"d*g" -> ["dog"],
"l*t" -> ["lot"],
"lo*" -> ["lot", "log"],
"l*g" -> ["log"],
"c*g" -> ["cog"],
"co*" -> ["cog"]
]이렇게 패턴을 통해 관리하게 되면 더 편하게 변환될 문자를 찾을 수 있다.
// BFS setup
Queue<String> queue = new LinkedList<>();
queue.add(beginWord);
Set<String> visited = new HashSet<>();
visited.add(beginWord);
int level = 1; // Start from level 1
// BFS loop
while (!queue.isEmpty()) {
int size = queue.size(); // Number of words to process at this level
for (int i = 0; i < size; i++) {
String currentWord = queue.poll();bfs가 시작되는 부분으로 큐에 시작 단어를 집어넣고 bfs를 실행한다. 각 레벨마다 한꺼번에 처리를 하게 되는데 각 단어마다 별도의 처리 횟수를 기록하고 있는 형태가 아니기 때문에 해당 레벨에서 큐에 들어있던 모든 값들을 다 처리하고 다음으로 넘어가게 구현되었다.
// Generate all possible patterns
for (int j = 0; j < wordLength; j++) {
String pattern = currentWord.substring(0, j) + '*' + currentWord.substring(j + 1);
// Get adjacent words for the pattern
List<String> adjacentWords = adjacencyMap.getOrDefault(pattern, new ArrayList<>());
for (String adjacentWord : adjacentWords) {
// If we find the endWord, return the level
if (adjacentWord.equals(endWord)) {
return level + 1;
}
// Add to queue and mark as visited if not already
if (!visited.contains(adjacentWord)) {
visited.add(adjacentWord);
queue.add(adjacentWord);
}
}
}
}
level++; // Increment the level after processing all words at the current level
}
return 0; // If endWord is not reachable
}다음은 처리 과정이다. 큐에서 뽑아낸 단어를 기준으로 패턴을 만든 뒤 맵에 들어있는 값을 가져온다. 맵에 값이 존재하지 않는다면 비어있는 리스트를 반환하게 되고 값이 들어있다면 변환 가능한 다음 값들을 추가하게 되고 방문 체크를 해준다. 만약 끝 단어를 찾았다면 현재 레벨에서 1을 더한 값을 결과로 반환하게 된다.
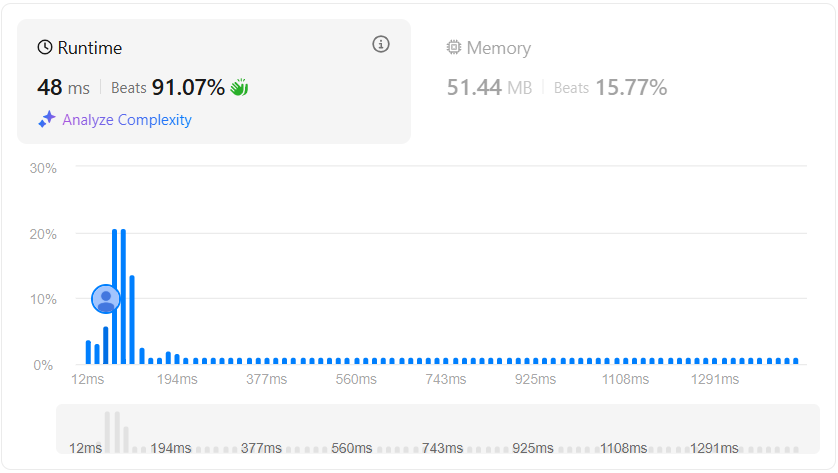
패턴을 통해 연산할 단어의 횟수를 줄이다 보니 차이가 어마어마했다.
전체 코드
기본
class Solution {
private class State{
public final String word;
public final int step;
private State(String word, int step){
this.word = word;
this.step = step;
}
}
private boolean isConvertable(String src, String dst){
char[] srcArr = src.toCharArray();
char[] dstArr = dst.toCharArray();
int diff = 0;
for(int i = 0; i < srcArr.length; i++){
if(srcArr[i] != dstArr[i]) diff++;
}
return diff == 1;
}
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
boolean[] isVisited = new boolean[wordList.size()];
Queue<State> que = new LinkedList<>();
que.add(new State(beginWord, 1));
while(!que.isEmpty()){
State state = que.poll();
if(state.word.equals(endWord)){
return state.step;
}
for(int i = 0; i < wordList.size(); i++){
String next = wordList.get(i);
if(!isConvertable(state.word, next)){
continue;
}
if(isVisited[i])
continue;
isVisited[i] = true;
que.add(new State(next, state.step + 1));
}
}
return 0;
}
}
패턴
import java.util.*;
class Solution {
public int ladderLength(String beginWord, String endWord, List<String> wordList) {
// Create a set of words for quick lookup
Set<String> wordSet = new HashSet<>(wordList);
if (!wordSet.contains(endWord)) {
return 0; // No possible transformation
}
// Preprocess the word list to create the adjacency map
Map<String, List<String>> adjacencyMap = new HashMap<>();
int wordLength = beginWord.length();
for (String word : wordSet) {
for (int i = 0; i < wordLength; i++) {
// Create patterns by replacing each character with '*'
String pattern = word.substring(0, i) + '*' + word.substring(i + 1);
adjacencyMap.computeIfAbsent(pattern, k -> new ArrayList<>()).add(word);
}
}
// BFS setup
Queue<String> queue = new LinkedList<>();
queue.add(beginWord);
Set<String> visited = new HashSet<>();
visited.add(beginWord);
int level = 1; // Start from level 1
// BFS loop
while (!queue.isEmpty()) {
int size = queue.size(); // Number of words to process at this level
for (int i = 0; i < size; i++) {
String currentWord = queue.poll();
// Generate all possible patterns
for (int j = 0; j < wordLength; j++) {
String pattern = currentWord.substring(0, j) + '*' + currentWord.substring(j + 1);
// Get adjacent words for the pattern
List<String> adjacentWords = adjacencyMap.getOrDefault(pattern, new ArrayList<>());
for (String adjacentWord : adjacentWords) {
// If we find the endWord, return the level
if (adjacentWord.equals(endWord)) {
return level + 1;
}
// Add to queue and mark as visited if not already
if (!visited.contains(adjacentWord)) {
visited.add(adjacentWord);
queue.add(adjacentWord);
}
}
}
}
level++; // Increment the level after processing all words at the current level
}
return 0; // If endWord is not reachable
}
}'알고리즘 > 코딩테스트-Grind75' 카테고리의 다른 글
| [Grind75-LeetCode] Maximum Profit in Job Scheduling JAVA (0) | 2024.12.05 |
|---|---|
| [Grind75-LeetCode] Basic Calculator JAVA (0) | 2024.12.04 |
| [Grind75-LeetCode] Find Median from Data Stream JAVA (0) | 2024.11.30 |
| [Grind75-LeetCode] Trapping Rain Water JAVA (1) | 2024.11.29 |
| [Grind75-LeetCode] Serialize and Deserialize Binary Tree JAVA (1) | 2024.11.28 |