[Grind75-LeetCode] Accounts Merge - Medium
접근
- dfs
- Union-Find
풀이
2차원 리스트로 사용자의 이름과 보유한 이메일 정보가 주어진다. 각
accounts [i][0]는 사용자의 이름을 나타내고 1번 인덱스부턴 보유 이메일이 들어있다. 이번 문제는 사용자가 보유한 중복되는 이메일을 병합하는 문제로 동명이인은 가려내고 같은 사용자의 이메일은 병합해 깔끔하게 출력하는 것이 목표이다.
accounts = [["John","johnsmith@mail.com","john_newyork@mail.com"],
["John","johnsmith@mail.com","john00@mail.com"],
["Mary","mary@mail.com"],
["John","johnnybravo@mail.com"]]위의 예제에서 John이라는 이름 가진 정보가 3개가 있다. 각 이메일의 정보를 봤을 때 0,1번 인덱스의 John에는 동일한 이메일이 존재하여 0,1 인덱스의 John은 동일 인물임을 알 수 있다. 동일 인물인 경우 이메일을 병합하여
["John","johnsmith@mail.com","john00@mail.com","john_newyork@mail.com"]한 개의 데이터로 만들어 준다. 나머지 Mary와 동명이인 John의 경우 병합할 내용이 없기 때문에 그대로 출력해 주면 되는데 이메일을 알파벳 순서로 정렬해야 하기에
["John","john00@mail.com","john_newyork@mail.com","johnsmith@mail.com"]형태로 반환하면 된다.
public List<List<String>> accountsMerge(List<List<String>> accounts) {
Map<String, String> emailNameMap = new HashMap<>();
Map<String, List<String>> emailMap = new HashMap<>();
for (List<String> account : accounts) {
String name = account.get(0);
for (int i = 1; i < account.size(); i++) {
String email = account.get(i);
emailNameMap.put(email, name);이번 문제는 Map을 사용한 그래프 탐색으로 풀어졌다. email을 Key로 name을 value로 갖는 Map 한 개와 email 간의 연결을 나타내는 emailMap 이렇게 두 개를 사용한다. 이메일이 들어있는 1번 인덱스부터 emailNameMap에 추가해 준다.
if (!emailMap.containsKey(email)) {
emailMap.put(email, new ArrayList<>());
}
if (i > 1) {
String prevEmail = account.get(i - 1);
emailMap.get(email).add(prevEmail);
emailMap.get(prevEmail).add(email);
}
}
}그리고 이메일들의 연결을 나타내는 emailMap에 현재 이메일이 들어있는지 확인하고 없다면 새로 추가해 준다. 그리고 두 번째 이메일부터 연결을 설정해 준다. 뒤에 병합을 위에 연결을 타고 타고 검사를 진행하게 될 것이다.
Set<String> isVisited = new HashSet<>();
List<List<String>> result = new ArrayList<>();
for (String email : emailMap.keySet()) {
if (isVisited.contains(email)) {
continue;
}
List<String> mergedAccount = new ArrayList<>();
dfs(email, isVisited, emailMap, mergedAccount);
Collections.sort(mergedAccount);
mergedAccount.add(0, emailNameMap.get(email));
result.add(mergedAccount);
}
return result;방문체크를 위해 Set을 사용해 주었다. 이미 체크한 이메일이라면 건너뛴다. 체크하지 않았던 이메일이라면 dfs를 사용해 병합을 실시해 주고 이메일을 알파벳 순으로 정렬한 뒤 병합된 리스트 0번에 사용자 이름을 넣고 결과 리스트에 추가해 준다.
private void dfs(String email, Set<String> isVisited, Map<String, List<String>> emailMap,
List<String> mergedAccount) {
isVisited.add(email);
mergedAccount.add(email);
for (String neighbor : emailMap.get(email)) {
if (!isVisited.contains(neighbor)) {
dfs(neighbor, isVisited, emailMap, mergedAccount);
}
}
}dfs를 통해 이메일을 병합하는 과정이다. dfs는 재귀를 통해 구현되었고 이메일은 호출 시 방문 체크를 수행하고 병합 리스트에 추가된다. emailMap에서 각 이메일에 연결되어 있는 모든 이메일에 대해 dfs를 수행한다. 참고로 emailMap.get()을 할 경우 List <String>의 값을 받아오는데 향상된 for문에서는 List <String>의 값을 순차 접근할 수 있게 알아서 처리해 준다.
//축소
for (String neighbor : emailMap.get(email)) {
if (!isVisited.contains(neighbor)) {
dfs(neighbor, isVisited, emailMap, mergedAccount);
}
}
//원본
for (List<String> ls : emailMap.get(email)) {
for(String neighbor : ls){
if (!isVisited.contains(neighbor)) {
dfs(neighbor, isVisited, emailMap, mergedAccount);
}
}
}즉 위의 두 코드가 동일하게 작동한다.
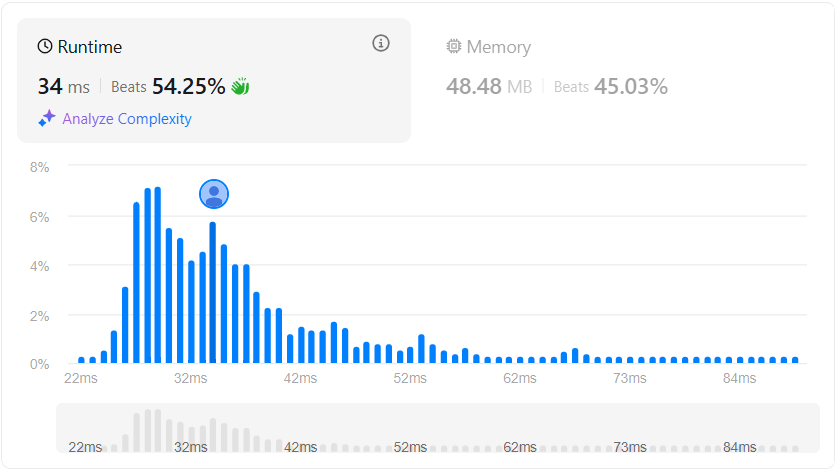
애매한 성능이 나왔다. 이 문제도 제출마다 변동이 좀 있었기에 변동 범위 밖의 22ms 코드를 가져와 분석해 봤다.
22ms
22ms로 풀어졌던 코드와 대부분의 평균 성능의 코드는 Union-Find 알고리즘으로 풀어진 코드였다. Union-Find는 트리 기반의 알고리즘으로 각 원소가 속한 집합을 추적하고 두 원소가 같은 집합에 속하는지 확인하거나 두 집합을 합치는 연산을 효율적으로 처리할 수 있는 구조이다. 이름과 같이 union, find 연산이 존재하는데 find 연산은 특정 원소가 속한 집합의 대표 또는 루트를 찾는 연산이고 union은 말 그대로 두 집합을 합치는 연산이다. Union-Find를 통해 서로 연결된 이메일을 한 계정으로 묶고 이를 통해 병합된 결과를 만드는 것이다.
public List<List<String>> accountsMerge(List<List<String>> accounts) {
int counter = 0;
HashMap<String, Integer> emailToInteger = new HashMap<>();
HashMap<String, String> emailToName = new HashMap<>();
int[] parents = new int[1000 * 9];
for (int i = 0; i < 9000; i++) {
parents[i] = -1;
}Map을 통해 이메일을 고유한 정수 counter를 사용해 매핑을 한다. 그리고 Union-Find를 위한 부모 배열을 생성하는데 최대 9000개 이메일을 처리 가능하고 모든 배열의 값은 자신을 부모로 설정하는 -1로 초기화한다.
for (List<String> account: accounts) {
String name = account.get(0);
String email = account.get(1);
if (!emailToInteger.containsKey(email)) {
emailToInteger.put(email, counter++);
emailToName.put(email, name);
}
for (int i = 2; i < account.size(); i++) {
email = account.get(i);
if (!emailToInteger.containsKey(email)) {
emailToInteger.put(email, counter++);
emailToName.put(email, name);
}
union(
emailToInteger.get(email),
emailToInteger.get(account.get(i - 1)),
parents
);
}
}계정들을 순회하며 이메일을 처리한다. 첫 번째 메일이 counter로 매핑되지 않았다면 매핑한 뒤 이름도 Map에 저장한다. 2번째 이메일부터 이메일정수맵에 이메일이 존재하지 않는다면 매핑을 실시하고 union 메서드를 실행해 준다.
public int find(int i, int[] parents) {
while (parents[i] >= 0) {
i = parents[i];
}
return i;
}
public void union(int u, int v, int[] parents) {
int rootU = find(u, parents);
int rootV = find(v, parents);
if (rootU == rootV) return;
if (parents[rootU] < parents[rootV]) {
parents[rootU] += parents[rootV];
parents[rootV] = rootU;
} else {
parents[rootV] += parents[rootU];
parents[rootU] = rootV;
}
}union이 나온 김에 find와 union 메서드를 설명하고 넘어가겠다. find 메서드는 부모 배열에서 해당 인덱스의 값이 0보다 크거나 같다면 다음 인덱스를 현재 인덱스의 값으로 설정하고 다시 실행한다. union 메서드의 경우 find를 통해 u와 v의 루트를 찾는다. 위에서 현재 이메일의 정수 값과 이전 이메일의 정수 값을 파라미터로 넘겨받았으니 find를 통해 현재 이메일의 루트와 이전 이메일의 루트를 찾게 된다. 만약 루트가 같다면 이미 같은 집합에 속해 병합할 필요가 없어 작업을 종료한다. 그렇지 않다면 작은 집합을 큰 집합에 합치는 Union by Rank 기법을 사용해 준다. 트리 구조를 따르게 되므로 parents 배열에 들어있는 값이 작을수록 트리의 레벨이 낮은 깊은 트리를 나타내며 rootU의 값이 rootV의 값 보다 작다는 것은 rootU가 더 깊은 트리이므로 rootV를 rootU 트리 및에 붙이는 것과 같다. 그러므로 rootU에 rootV의 값을 더 해 트리 레벨을 늘려주고 rootV의 값을 rootU로 설정해 부모임을 나타내준다.
HashMap<Integer, TreeSet> groups = new HashMap<>();
for (String email: emailToInteger.keySet()) {
int root = find(emailToInteger.get(email), parents);
if (!groups.containsKey(root)) {
groups.put(root, new TreeSet<>());
}
groups.get(root).add(email);
}다음은 이메일 위에서 만들어진 이메일정수 맵을 통해 정수값 별로 그룹화하는 과정이다. 정수값을 Key로 가지고 TreeSet을 value로 가지는 groups 맵을 선언 하여 할당해 주는데 각 이메일의 루트 값을 찾아 루트 값을 기준으로 모든 이메일을 추가해 준다. 그렇게 결과인 사용자마다 병합된 이메일 주소를 만들 수 있다. TreeSet은 Set과 같은 집합 구조인데 내부 이진 검색 트리를 사용해 구현되기 때문에 데이터 삽입 시 자동으로 오름차순 정렬이 된다. TreeSet을 사용하여 추가 정렬 없이 결과물을 바로 사용할 수 있다.
List<List<String>> mergedAccounts = new ArrayList<>();
for (Integer root: groups.keySet()) {
String name = emailToName.get(groups.get(root).first());
List<String> mergedAccount = new ArrayList<>();
mergedAccount.add(name);
mergedAccount.addAll(groups.get(root));
mergedAccounts.add(mergedAccount);
}
return mergedAccounts;결과 반환을 위해 조작하는 과정이다. 해당 그룹에 속하는 첫 번째 이메일의 이름을 가져와 사용자 이름을 0번 인덱스로 삽입하고 나머지 이메일들을 모두 추가해준다. 해당 과정을 사용자마다 진행해 주어 결과 반환을 위한 리스트를 만들게 된다.
전체 코드
dfs
class Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
Map<String, String> emailNameMap = new HashMap<>();
Map<String, List<String>> emailMap = new HashMap<>();
for (List<String> account : accounts) {
String name = account.get(0);
for (int i = 1; i < account.size(); i++) {
String email = account.get(i);
emailNameMap.put(email, name);
if (!emailMap.containsKey(email)) {
emailMap.put(email, new ArrayList<>());
}
if (i > 1) {
String prevEmail = account.get(i - 1);
emailMap.get(email).add(prevEmail);
emailMap.get(prevEmail).add(email);
}
}
}
Set<String> isVisited = new HashSet<>();
List<List<String>> result = new ArrayList<>();
for (String email : emailMap.keySet()) {
if (!isVisited.contains(email)) {
List<String> mergedAccount = new ArrayList<>();
dfs(email, isVisited, emailMap, mergedAccount);
Collections.sort(mergedAccount);
mergedAccount.add(0, emailNameMap.get(email));
result.add(mergedAccount);
}
}
return result;
}
private void dfs(String email, Set<String> isVisited, Map<String, List<String>> emailMap, List<String> mergedAccount) {
isVisited.add(email);
mergedAccount.add(email);
for (String neighbor : emailMap.get(email)) {
if (!isVisited.contains(neighbor)) {
dfs(neighbor, isVisited, emailMap, mergedAccount);
}
}
}
}
22ms - Union Find
class Solution {
public List<List<String>> accountsMerge(List<List<String>> accounts) {
int counter = 0;
HashMap<String, Integer> emailToInteger = new HashMap<>();
HashMap<String, String> emailToName = new HashMap<>();
int[] parents = new int[1000 * 9];
for (int i = 0; i < 9000; i++) {
parents[i] = -1;
}
for (List<String> account: accounts) {
String name = account.get(0);
String email = account.get(1);
if (!emailToInteger.containsKey(email)) {
emailToInteger.put(email, counter++);
emailToName.put(email, name);
}
for (int i = 2; i < account.size(); i++) {
email = account.get(i);
if (!emailToInteger.containsKey(email)) {
emailToInteger.put(email, counter++);
emailToName.put(email, name);
}
union(
emailToInteger.get(email),
emailToInteger.get(account.get(i - 1)),
parents
);
}
}
HashMap<Integer, TreeSet> groups = new HashMap<>();
for (String email: emailToInteger.keySet()) {
int root = find(emailToInteger.get(email), parents);
if (!groups.containsKey(root)) {
groups.put(root, new TreeSet<>());
}
groups.get(root).add(email);
}
List<List<String>> mergedAccounts = new ArrayList<>();
for (Integer root: groups.keySet()) {
String name = emailToName.get(groups.get(root).first());
List<String> mergedAccount = new ArrayList<>();
mergedAccount.add(name);
mergedAccount.addAll(groups.get(root));
mergedAccounts.add(mergedAccount);
}
return mergedAccounts;
}
public int find(int i, int[] parents) {
while (parents[i] >= 0) {
i = parents[i];
}
return i;
}
public void union(int u, int v, int[] parents) {
int rootU = find(u, parents);
int rootV = find(v, parents);
if (rootU == rootV) return;
if (parents[rootU] < parents[rootV]) {
parents[rootU] += parents[rootV];
parents[rootV] = rootU;
} else {
parents[rootV] += parents[rootU];
parents[rootU] = rootV;
}
}
}'알고리즘 > 코딩테스트-Grind75' 카테고리의 다른 글
| [Grind75-LeetCode] Word Break JAVA (1) | 2024.11.10 |
|---|---|
| [Grind75-LeetCode] Sort Colors JAVA (1) | 2024.11.09 |
| [Grind75-LeetCode] Time Based Key-Value Store JAVA (0) | 2024.11.07 |
| [Grind75-LeeCode] Lowest Common Ancestor of a Binary Tree JAVA (1) | 2024.11.06 |
| [Grind75-LeetCode] Merge Intervals JAVA (0) | 2024.11.05 |