[Grind75-LeetCode] Number of Islands - Medium
접근
- bfs
- dfs
풀이
0과 1로 이루어진 2차원 배열에서 1이 섬을 나타내고 0이 물을 나타낼 때 좌표 평면 위에 몇 개의 섬이 존재하는지 구하는 문제이다. 비슷한 유형이 굉장히 많은 문제로 비슷한 문제를 풀어 올렸던 기억이 있다.
2024.09.26 - [알고리즘/코딩테스트-백준] - [백준] 단지번호 붙이기 JAVA
[백준] 단지번호 붙이기 JAVA
[백준] 단지번호 붙이기 - SILVER I 2667번2667번: 단지번호붙이기 (acmicpc.net)접근bfs풀이2차원 배열로 주어지는 지도를 탐색하며 붙어 지도에 총 몇 단지가 존재하는지와 단지를 이루는 집들의 수를
kwang2134.tistory.com
백준의 단지번호 붙이기 문제와 동일하나 훨씬 간단한 문제이다. 역시나 bfs와 dfs를 통해 풀 것이고 2차원 배열의 모든 좌표를 방문해야 하다 보니 두 방식 간의 시간 복잡도는 동일하다. 그렇기 때문에 재귀로 구현한 dfs와 큐를 통해 구현한 bfs의 성능 차이가 포인트인 거 같다.
BFS (Queue)
큐를 이용한 bfs 방식이다. 먼저 말하고 시작하자면 큐의 입출력 오버헤드로 인해 재귀로 구현된 dfs보다 성능이 떨어진다.
private static final int[] dx = {0, 0, 1, -1};
private static final int[] dy = {1, -1, 0, 0};
public int numIslands(char[][] grid) {
boolean[][] isVisited = new boolean[grid.length][grid[0].length];
int result = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
int island = grid[i][j] - '0';
if (!isVisited[i][j] && island == 1) {
bfs(isVisited, grid, i, j);
result++;
}
}
}
return result;
}코드 부분으로 넘어가서 구현할 메서드 부분이다. 2차원 배열을 순회하며 방문하지 않았고 해당 좌표가 육지(1)이라면 bfs 메서드를 실행한다. bfs 메서드 실행마다 연결된 육지(1)의 모든 부분을 체크하므로 한 개의 섬을 찾았다는 뜻에서 result를 증가시킨다.
public void bfs(boolean[][] isVisited, char[][] grid, int x, int y) {
Queue<int[]> que = new LinkedList<>();
que.offer(new int[]{x, y});
isVisited[x][y] = true;
while (!que.isEmpty()) {
int[] XY = que.poll();
for (int d = 0; d < 4; d++) {
int nx = XY[0] + dx[d];
int ny = XY[1] + dy[d];
if (nx < 0 || nx >= grid.length || ny < 0 || ny >= grid[nx].length || grid[nx][ny] == '0') {
continue;
}
if (isVisited[nx][ny]) {
continue;
}
que.offer(new int[]{nx, ny});
isVisited[nx][ny] = true;
}
}
}bfs 메서드이다. 늘 똑같은 방식으로 구현했으며 메서드를 실행하며 상하좌우로 붙어있는 구역의 방문체크가 핵심이다. 처음 방문하는 육지(1)를 발견하면 그 육지와 상하좌우로 연결된 모든 육지를 탐색해 방문배열에 입력하고 다음 육지 찾으러 간다.
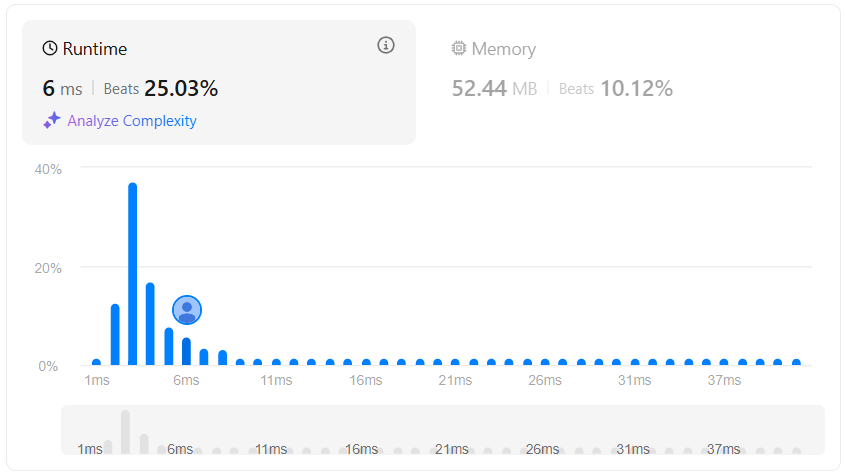
평균보다 낮은 성능이다. 앞 쪽의 코드는 거의 다 재귀로 구현된 코드들이다.
DFS (재귀)
재귀를 통해 구현되는 방식으로 큐나 스택으로 인한 입출력 오버헤드가 없어 비교적 빠른 실행 시간을 얻을 수 있다.
public void dfs(boolean[][] isVisited, char[][] grid, int x, int y) {
for (int d = 0; d < 4; d++) {
int nx = x + dx[d];
int ny = y + dy[d];
if (nx < 0 || nx >= grid.length || ny < 0 || ny >= grid[nx].length || grid[nx][ny] == '0') {
continue;
}
if (isVisited[nx][ny]) {
continue;
}
isVisited[nx][ny] = true;
dfs(isVisited, grid, nx, ny);
}
}bfs 메서드만 dfs로 바꿨다. 큐에 대한 처리가 사라지고 다시 dfs를 재귀호출 하는 형태로 바뀌었다.

6ms -> 4ms로 실행 시간이 조금 단축되긴 했지만 아직 앞에는 1,2, 3ms의 코드들이 존재한다. 1ms와 2ms의 코드 두 개를 가져와 분석해 봤다.
2ms 코드
2ms 성능을 가진 코드는 동작 방식은 방문 배열을 사용하지 않고 육지(1) 발견 시 해당 구역과 연결된 구역을 다 0으로 바꾸는 방법으로 구현되었다. 해당 섬을 통째로 0으로 바꿔버려 다음 섬 탐색 시 물(0)로 판단하게 해 버리는 것이었다.
public int numIslands(char[][] grid) {
int row = grid.length;
int col = grid[0].length;
int count = 0;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (grid[i][j] == '1') {
count++;
dfs(grid, i, j);
}
}
}
return count;
}dfs를 수행하는 메서드 외에 기본 numIslands 메서드는 동일한 모습이다.
void dfs(char[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] != '1') {
return;
}
grid[i][j] = '0';
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
}작업을 수행하는 핵심 메서드로 좌표가 배열 범위 밖이거나 육지(1)가 아니고 물(0)이면 진행을 종료한다. 만약 좌표가 배열 범위 내이고 육지(1)라면 해당 좌표를 물(0)로 바꾸고 상하좌우로 다음 지역을 탐색한다. 이렇게 방문배열을 따로 두지 않고 체크한 곳을 물(0)로 바꿔버려 코드를 줄였다.

1ms
1ms의 코드도 육지에 해당하는 좌표에 값을 *라는 의미 없는 값으로 바꿔 다음 탐색 시 육지로 인식하지 못하게 하는 방식으로 구현되었다. 사실 코드가 좀 더 세분화된 것 말고는 거의 동일한 내용이다.
int rows;
int cols;
int islands = 0;
public int numIslands(char[][] grid) {
rows = grid.length;
cols = grid[0].length;
for (int row = 0; row < rows; row++)
check(grid, row);
return islands;
}열과 행 그리고 섬의 개수를 전역 변수로 두고 배열을 체크한다.
public void check(final char[][] grid, int row) {
final char[] finalRow = grid[row];
for (int col = 0; col < cols; ++col)
if (finalRow[col] == '1') {
bfs(grid, row, col);
++islands;
}
}2중 for문으로 체크하던 부분을 메서드로 뽑아 한 줄씩 체크하는 형태로 바뀌었다. 그 외에는 동일하다.
public void bfs(char[][] grid, int row, int col) {
grid[row][col] = '*';
if (row > 0 && grid[row - 1][col] == '1')
bfs(grid, row - 1, col);
if (row + 1 < rows && grid[row + 1][col] == '1')
bfs(grid, row + 1, col);
if (col > 0 && grid[row][col - 1] == '1')
bfs(grid, row, col - 1);
if (col + 1 < cols && grid[row][col + 1] == '1')
bfs(grid, row, col + 1);
}마지막 함수를 실행하는 부분인데 이름이 bfs다. 메서드 재귀호출은 함수 호출 스택을 사용하므로 bfs보다 dfs가 맞지만 풀어진 코드를 들고 온 것이기 때문에 내버려 두었다. 앞의 2ms 코드와 동일하게 0으로 바꾸는 대신 *로 바꾸는 내용이다.

2ms 코드와 1ms 코드에서 차이가 발생하는 이유
겉으로 보기엔 똑같은 방법으로 구현되어 있는 코드인데 사소하지만 왜 1ms라는 성능 차이가 발생하는가? 그 이유는 1ms 코드의 CPU 캐시 활용과 JVM 최적화를 위한 부분이 더 잘 작성되었기 때문이다. numsIsland와 check 메서드로 나눠 1차원 배열에 접근하게 한 것과 final 키워드를 사용한 것에서 발생한다.
2ms의 코드의 경우 매번 2차원 배열에 접근하게 된다. 2차원 배열 접근 시 발생하는 과정으로
- grid 배열의 메모리 주소 계산
- row 인덱스로 해당 행의 주소 계산
- col 인덱스로 최종 요소의 주소 계산
- 메모리에서 값 읽기
과정이 발생하는데 grid의 기본 주소를 찾고 i 인덱스로 행 참조 배열 접근한 뒤 찾은 행의 시작 주소 + (j * sizeof(char)) 형태의 메모리 주소 계산이 매 반복마다 일어나게 된다. 그러나 1ms의 코드는 메서드를 분리하며 1차원 배열로 접근하게 구현되어 있다. 1ms 코드의 접근 방식으로
- 행 전체를 한 번만 가져와서 지역 변수에 저장
- col 인덱스로 최종 요소의 주소 계산
- 메모리에서 값 읽기
행 전체를 가져온 뒤 1차원 배열로 접근하며 grid의 기본 주소를 찾고 row 인덱스로 행 참조 배열 접근한 뒤 행의 시작 주소를 finalRow에 저장하는 과정은 한 번만 수행되고 반복문을 통해 finalRow의 시작 주소 + (col * sizeof(char)) 를 구하는 과정만 여러 번 수행된다. 또한 1차원 배열은 연속된 메모리 접근으로 CPU 캐시를 통해 CPU가 다음 접근을 예측할 수 있기 때문에 캐시 히트가 자주 발생할 수 있지만 2차원 배열의 경우 매번 새로운 계산으로 예측이 힘들다는 것이다. 1차원 배열과 2차원 배열을 사용하는 것 외에도 가져온 행을 final 키워드로 선언해 불변을 보장하게 함으로써 JVM은 해당 배열이 변경된다는 가정을 하지 않아도 되기에 여러 가지 최적화가 일어날 수 있다.
표를 통해 정리를 해보자면
| 1ms (1차원 배열) | 2ms (2차원 배열) | |
| CPU 캐시 | 행의 시작 주소가 캐시에 유지됨 | 매번 새로운 주소 계산으로 캐시 활용도 저하 |
| 주소 계산 | 단순 오프셋 계산 (1단계) | 다단계 주소 계산 (3단계) |
| 캐시 히트 | 연속된 메모리 접근으로 CPU가 다음 접근 예측 가능 | 매번 새로운 계산으로 예측이 어려움 |
| JVM 최적화 | final 키워드 사용으로 불변성 보장 -> 단순한 1차원 배열 접근 패턴은 더 많은 최적화 기회 제공 |
final 키워드 X 불변성을 보장하지 않음 -> JVM이 매번 변경을 확인해야 함 |
이러한 차이들로 인해 사소한 차이가 발생하는 것으로 생각된다.
전체 코드
BFS & DFS
class Solution {
private static final int[] dx = {0, 0, 1, -1};
private static final int[] dy = {1, -1, 0, 0};
public int numIslands(char[][] grid) {
boolean[][] isVisited = new boolean[grid.length][grid[0].length];
int result = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[i].length; j++) {
int island = grid[i][j] - '0';
if (!isVisited[i][j] && island == 1) {
//bfs(isVisited, grid, i, j);
dfs(isVisited, grid, i, j);
result++;
}
}
}
return result;
}
public void dfs(boolean[][] isVisited, char[][] grid, int x, int y) {
for (int d = 0; d < 4; d++) {
int nx = x + dx[d];
int ny = y + dy[d];
if (nx < 0 || nx >= grid.length || ny < 0 || ny >= grid[nx].length || grid[nx][ny] == '0') {
continue;
}
if (isVisited[nx][ny]) {
continue;
}
isVisited[nx][ny] = true;
dfs(isVisited, grid, nx, ny);
}
}
public void bfs(boolean[][] isVisited, char[][] grid, int x, int y) {
Queue<int[]> que = new LinkedList<>();
que.offer(new int[]{x, y});
isVisited[x][y] = true;
while (!que.isEmpty()) {
int[] XY = que.poll();
for (int d = 0; d < 4; d++) {
int nx = XY[0] + dx[d];
int ny = XY[1] + dy[d];
if (nx < 0 || nx >= grid.length || ny < 0 || ny >= grid[nx].length || grid[nx][ny] == '0') {
continue;
}
if (isVisited[nx][ny]) {
continue;
}
que.offer(new int[]{nx, ny});
isVisited[nx][ny] = true;
}
}
}
}
2ms - 육지 -> 물 변경
class Solution {
public int numIslands(char[][] grid) {
int row = grid.length;
int col = grid[0].length;
int count = 0;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
if (grid[i][j] == '1') {
count++;
dfs(grid, i, j);
}
}
}
return count;
}
void dfs(char[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] != '1') {
return;
}
grid[i][j] = '0';
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
}
}
1ms - 최적화
class Solution {
int rows;
int cols;
int islands = 0;
public int numIslands(char[][] grid) {
rows = grid.length;
cols = grid[0].length;
for (int row = 0; row < rows; row++)
check(grid, row);
return islands;
}
public void check(final char[][] grid, int row) {
final char[] finalRow = grid[row];
for (int col = 0; col < cols; ++col)
if (finalRow[col] == '1') {
bfs(grid, row, col);
++islands;
}
}
public void bfs(char[][] grid, int row, int col) {
grid[row][col] = '*';
if (row > 0 && grid[row - 1][col] == '1')
bfs(grid, row - 1, col);
if (row + 1 < rows && grid[row + 1][col] == '1')
bfs(grid, row + 1, col);
if (col > 0 && grid[row][col - 1] == '1')
bfs(grid, row, col - 1);
if (col + 1 < cols && grid[row][col + 1] == '1')
bfs(grid, row, col + 1);
}
}'알고리즘 > 코딩테스트-Grind75' 카테고리의 다른 글
| [Grind75-LeetCode] Search in Rotated Sorted Array JAVA (0) | 2024.11.02 |
|---|---|
| [Grind75-LeetCode] Rotting Oranges JAVA (0) | 2024.11.01 |
| [Grind75-LeetCode] Validate Binary Search Tree JAVA (0) | 2024.10.30 |
| [Grind75-LeetCode] Min Stack JAVA (0) | 2024.10.29 |
| [Grind75-LeetCode] Product of Array Except Self JAVA (0) | 2024.10.28 |